A survey on federated learning
Published:
- 论文链接:https://www.sciencedirect.com/science/article/pii/S0950705121000381?via%3Dihub
- 会议/期刊: Knowledge-based systems (CCFC SCI一区)
- Keywords:Federaled learning, Privacy protection
Abstract
联合学习是在一个中央聚合器的协调下,多个客户机协作解决机器学习问题的一种设置。该设置还允许分散训练数据,以确保每个设备的数据隐私。
联邦学习坚持两大思想:局部计算和模型传输,降低了传统集中式机器学习方法带来的一些系统隐私风险和成本。
客户端原始数据存储在本地,不允许交换和迁移。通过联合学习,每个设备使用本地数据进行本地训练,然后将模型上传到服务器进行聚合,最后服务器将模型更新发送给参与者,从而达到学习目标。本文从数据划分、隐私机制、机器学习模型、通信体系结构和系统异构五个方面系统地介绍了联邦学习的现有工作,为该领域的研究提供了一个全面的综述。
然后,梳理了联邦学习目前面临的挑战和未来的研究方向。最后,总结了现有联邦学习的特点,并分析了当前联邦学习的实际应用。
1. Introduction
1.1 Backgrounds of federated learning
需要解决的问题:
- 数据安全
- 数据孤岛(data islands)
联邦学习提供了一种隐私保护机制,可以有效地利用终端设备的计算资源对模型进行训练,防止隐私信息在数据传输过程中被泄露。
联邦学习主要通过交换经过加密处理的参数来保护用户隐私,而攻击者无法获取源数据。
\[联邦学习 = 分布式训练 + 隐私保护机制\]联邦学习根据数据的分布可以分为:
- 横向联邦学习:适用于两个数据集的用户特征重叠较多而用户重叠较少的情况
- 纵向联邦学习:两个数据集的用户特征很少重叠,但用户重叠较多的情况
- 联邦迁移学习:两个数据集的用户和用户特征很少重叠的情况
1.2 Challenges to dederated learning
- 隐私保护
- 数据量不足:每个移动设备上数据量可能不足
- 统计异质性:节点设备上的数据可能是非独立同分布的
1.3 Main contributions
2. Related works
2.1 Definition of federated learning
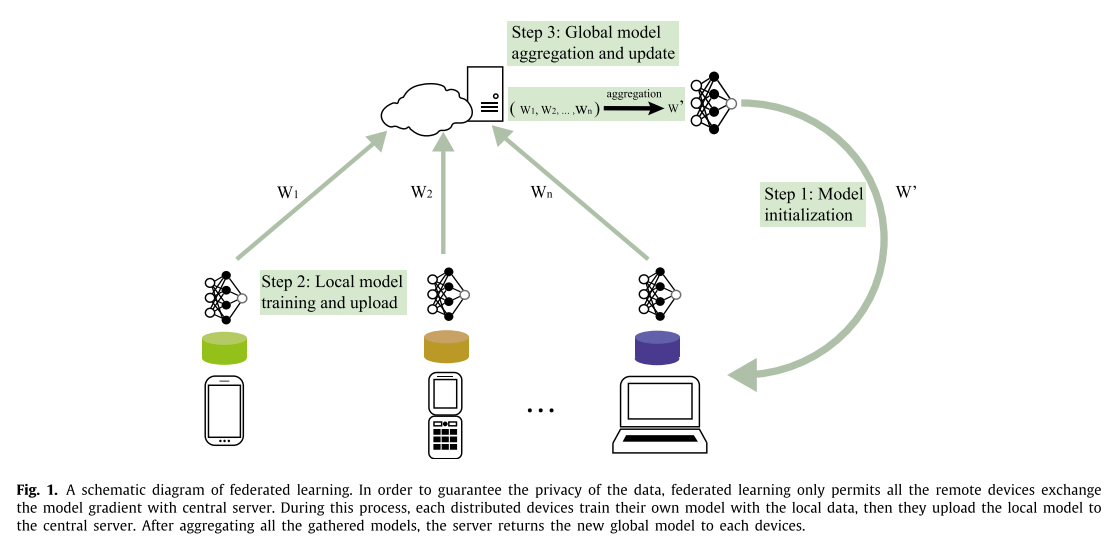
步骤:
- 服务器将初始模型发送到每个设备
- 分布式设备使用本地数据进行训练
- 服务器将收集到的本地模型聚合到全局模型,
- 最后再将全局模型替换到分布式设备上
2.2 The development of federated learning
举例说明了什么是联邦学习,所以这部分的标题为什么叫 ‘development’?
3. Categorizations of federated learing
本节从数据分区、隐私机制、适用的机器学习模型、通信体系结构和解决异构问题的方法五个方面总结了联邦学习的分类。
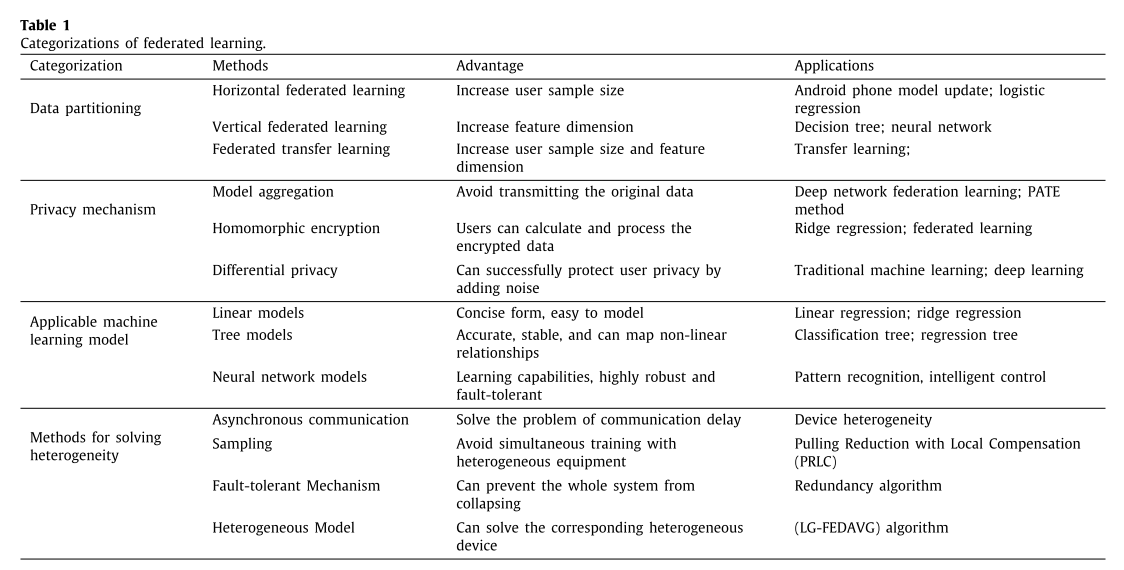
3.1 Data partition
根据数据的样本空间和特征空间的不同分布模式,分为:横向联邦、纵向联邦和联邦迁移,如下图所示:
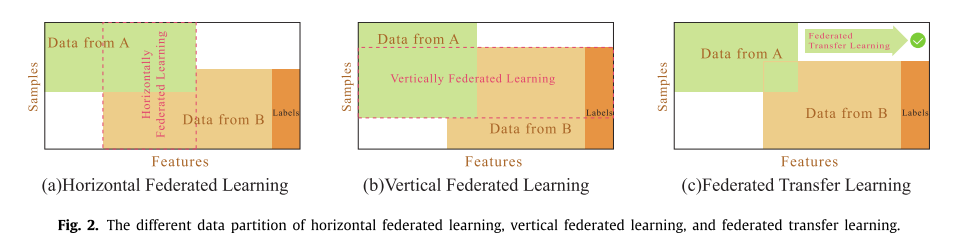
3.1.1 Horizontal federated learning
适用于两个数据集的用户特征重叠较多而用户重叠较少的情况。
具体的做法是,将数据集按照用户维度水平分割,然后取出用户特征相同但用户不完全相同的部分进行训练。因此,不同行中的数据具有相同的数据维度。
水平联合学习可以增加用户样本的大小。 例如,在不同的区域有两个提供相同服务的提供者,他们的用户组来自各自的区域,彼此之间很少有重叠。但是,它们的业务非常相似,所以记录的用户特征是相同的。在这方面,我们可以使用横向联邦学习来训练一个模型,这样不仅可以增加训练样本的总数,而且可以提高模型的准确性。
3.1.2 Vertical federated learning
纵向联合学习是在两个数据集的用户特征很少重叠,但用户重叠较多的情况下实现的。
具体做法:将数据集垂直划分(按用户特征维度),然后取出用户相同但用户特征不完全相同的部分数据进行训练。换句话说,不同列中的数据具有相同的用户(按用户对齐)。
纵向联合学习可以增加训练数据的特征维数。 例如,有两个不同的机构,一个是在一个地方的银行,另一个是在同一个地方的电子商务公司。他们的用户群可能包括该地区的大多数居民,因此有一个更大的用户交集。但是,由于银行记录了用户的收入和支出行为以及信用评级,而电子商务记录了用户的浏览和购买历史,所以它们的用户特征几乎没有交集。纵向联合学习就是将这些不同的特征以加密的状态聚合起来,以增强模型的能力。目前,许多机器学习模型,如逻辑回归模型、树形结构模型和神经网络模型都逐渐被证明是基于这个联邦系统的。
3.1.3 Federated transfer learning
在两个数据集的用户和用户特征很少重叠的情况下,不分割数据,但可以使用迁移学习克服数据或标签的缺乏。 这种方法称为联邦迁移学习。
例如,有两个不同的机构,一个是中国的电子商务,另一个是美国的社交应用。由于地域的限制,两家机构的用户群体几乎没有重叠。同时,由于机构类型的不同,两个数据集的数据特征仅是重叠部分的一小部分。在这种情况下,为了进行有效的联合学习,必须引入迁移学习来解决单侧数据量小、标签样本小的问题,从而提高模型的有效性。迁移学习最适合的情况是当您试图优化任务的性能,但没有足够的相关数据进行培训。例如,医院放射科很难收集大量的 x 线扫描,以建立一个良好的放射诊断系统。此时,迁移学习将帮助我们学习其他相关但不同的任务,如图像识别任务,学习一个放射诊断系统。通过联邦迁移学习,既可以保证数据的私密性,又可以将辅助任务的模型迁移到指导者学习中,解决了数据量小的问题。
3.2 Privacy mechanisms
联合学习最重要的特点是合作客户端可以将自己的数据保存在本地,并且需要共享模型信息来训练目标模型,但是模型信息也会泄露一些私有信息。保护联邦隐私的常用方法是模型聚合、同态加密和差分隐私。
3.2.1 Model aggregation
通过总结各方的模型参数来训练全局模型,从而避免在训练过程中传输原始数据。
3.2.2 Homomorphic encryption
用户可以通过此方法对加密后的数据进行计算和处理,但在处理过程中不会泄露原始数据
3.2.3 Differential privacy
3.3 Applicable machine learning models
3.3.1 Linear models
分别在 linear regression, ridge regression and lasso regression 上取得了较好的性能
3.3.2 Tree models
可用于训练单个或多个决策树,如梯度增强决策树和随机森林
3.3.3 Neural network models
3.4 Communication architecture
3.5 Methods for solving heterogeneity
在联合学习的应用场景中,设备的差异会影响整个训练过程的效率低下。为了解决系统异构问题,有四种分流方式:异步通信、设备采样、容错机制和模型异构。
3.5.1 Asynchronous communication
异步通信机制可以很好地解决设备分散的问题
3.5.2 Sampling
在联合学习中,并不是每个设备都需要参与到每个迭代训练过程中。在一些联合学习场景中,设备被选中参与训练,而在场景的另一部分,设备主动参与训练。
3.5.3 Fault-tolerant mechanism
在不稳定的网络环境中,容错机制可以防止系统崩溃,特别是在分布式环境中。
3.5.4 Model heterogeneity
为了解决数据异构问题,联邦学习网络主要分为三种建模方式:
- 单个设备有自己的模型
- 训练一个适用于所有设备的全局模型
- 为特定的任务训练特定的模型